1.1 Concepto de base de datos distribuidas
Bases de Datos Distribuidas Definición:
Consiste en una colección de sitios, conectados por medio de algún tipo de red de comunicación, en el cual Cada sitio es un sistema de BD completo por derecho propio, pero Los sitios ha acordado trabajar juntos, a fin de que un usuario de cualquier sitio pueda acceder a los datos desde cualquier lugar de la red, exactamente como si los datos estuvieran guardados en el propio sitio del usuario.
VENTAJAS
- Refleja una estructura organizacional - los fragmentos de la base de datos se ubican en los departamentos a los que tienen relación.
- - los fragmentos de la base de datos se ubican en los departamentos a los que tienen relación.
- Autonomía local - un departamento puede controlar los datos que le pertenecen.
- Disponibilidad - un fallo en una parte del sistema solo afectará a un fragmento, en lugar de a toda la base de datos.
- Rendimiento - los datos generalmente se ubican cerca del sitio con mayor demanda, también los sistemas trabajan en paralelo, lo cual permite balancear la carga en los servidores.
- Economía - es más barato crear una red de muchas computadoras pequeñas, que tener una sola computadora muy poderosa.
- Modularidad - se pueden modificar, agregar o quitar sistemas de la base de datos distribuida sin afectar a los demás sistemas (módulos).
DESVENTAJAS
- Complejidad - Se debe asegurar que la base de datos sea transparente, se debe lidiar con varios sistemas diferentes que pueden presentar dificultades únicas. El diseño de la base de datos se tiene que trabajar tomando en cuenta su naturaleza distribuida, por lo cual no podemos pensar en hacer joins que afecten varios sistemas.
- Economía - la complejidad y la infraestructura necesaria implica que se necesitará una mayor mano de obra.
- Seguridad - se debe trabajar en la seguridad de la infraestructura así como cada uno de los sistemas.
- Integridad - Se vuelve difícil mantener la integridad, aplicar las reglas de integridad a través de la red puede ser muy caro en términos de transmisión de datos.
- Falta de experiencia - las bases de datos distribuidas son un campo relativamente nuevo y poco común por lo cual no existe mucho personal con experiencia o conocimientos adecuados.
- Carencia de estándares - aún no existen herramientas o metodologías que ayuden a los usuarios a convertir un DBMS centralizado en un DBMS distribuido.
- Diseño de la base de datos se vuelve más complejo - además de las dificultades que generalmente se encuentran al diseñar una base de datos, el diseño de una base de datos distribuida debe considerar la fragmentación, replicación y ubicación de los fragmentos en sitios específicos.
1.2 Diseño de Bases de Datos Distribuidas
El diseño de un sistema de base de datos distribuido implica la toma de decisiones sobre la ubicación de los programas que accederán a la base de datos y sobre los propios datos que constituyen esta última.
A lo largo de los diferentes puestos que configuren una red de ordenadores. La ubicación de los programas, a priori, no debería suponer un excesivo problema dado que se puede tener una copia de ellos en cada máquina de la red (de hecho, en este documento se asumirá que así es). Sin embargo, cuál es la mejor opción para colocar los datos: en una gran máquina que albergue a todos ellos, encargada de responder a todas las peticiones del resto de las estaciones - sistema de base de datos centralizado -, o podríamos pensar en repartir las relaciones, las tablas, por toda la red. En el supuesto que nos decantásemos por esta segunda opción, ¿qué criterios se deberían seguir para llevar a cabo tal distribución? ¿Realmente este enfoque ofrecerá un mayor rendimiento que el caso centralizado? ¿Podría optarse por alguna otra alternativa? En los párrafos sucesivos se tratará de responder a estas cuestiones.
Tradicionalmente se ha clasificado la organización de los sistemas de bases de datos distribuidos sobre tres dimensiones: el nivel de compartición, las características de acceso a los datos y el nivel de conocimiento de esas características de acceso (vea la figura 1). El nivel de compartición presenta tres alternativas: inexistencia, es decir, cada aplicación y sus datos se ejecutan en un ordenador con ausencia total de comunicación con otros programas u otros datos; se comparten sólo los datos y no los programas, en tal caso existe una réplica de las aplicaciones en cada máquina y los datos viajan por la red; y, se reparten datos y programas, dado un programa ubicado en un determinado sitio, éste puede solicitar un servicio a otro programa localizado en un segundo lugar, el cual podrá acceder a los datos situados en un tercer emplazamiento. Como se comentó líneas atrás, en este caso se optará por el punto intermedio de compartición.
Respecto a las características de acceso a los datos existen dos alternativas principalmente: el modo de acceso a los datos que solicitan los usuarios puede ser estático, es decir, no cambiará a lo largo del tiempo, o bien, dinámico. El lector podrá comprender fácilmente la dificultad de encontrar sistemas distribuidos reales que puedan clasificarse como estáticos. Sin embargo, lo realmente importante radica, estableciendo el dinamismo como base, cómo de dinámico es, cuántas variaciones sufre a lo largo del tiempo. Esta dimensión establece la relación entre el diseño de bases de datos distribuidas y el procesamiento de consultas.
La tercera clasificación es el nivel de conocimiento de las características de acceso. Una posibilidad es, evidentemente, que los diseñadores carezcan de información alguna sobre cómo los usuarios acceden a la base de datos. Es una posibilidad teórica, pero sería muy laborioso abordar el diseño de la base de datos con tal ausencia de información. Lo más práctico sería conocer con detenimiento la forma de acceso de los usuarios o, en el caso de su imposibilidad, conformarnos con una información parcial de ésta.
El problema del diseño de bases de datos distribuidas podría enfocarse a través de esta trama de opciones. En todos los casos, excepto aquel en el que no existe compartición, aparecerán una serie de nuevos problemas que son irrelevantes en el caso centralizado.
A la hora de abordar el diseño de una base de datos distribuida podremos optar principalmente por dos tipos de estrategias: la estrategia ascendente y la estrategia descendente. Ambos tipos no son excluyentes, y no resultaría extraño a la hora de abordar un trabajo real de diseño de una base de datos que se pudiesen emplear en diferentes etapas del proyecto una u otra estrategia. La estrategia ascendente podría aplicarse en aquel caso donde haya que proceder a un diseño a partir de un número de pequeñas bases de datos existentes, con el fin de integrarlas en una sola. En este caso se partiría de los esquemas conceptuales locales y se trabajaría para llegar a conseguir el esquema conceptual global. Aunque este caso se pueda presentar con facilidad en la vida real, se prefiere pensar en el caso donde se parte de cero y se avanza en el desarrollo del trabajo siguiendo la estrategia descendente. La estrategia descendente debería resultar familiar a la persona que posea conocimientos sobre el diseño de bases de datos, exceptuando la fase del diseño de la distribución. Pese a todo, se resumirán brevemente las etapas por las que se transcurre.
Todo comienza con un análisis de los requisitos que definirán el entorno del sistema en aras a obtener tanto los datos como las necesidades de procesamiento de todos los posibles usuarios del banco de datos. Igualmente, se deberán fijar los requisitos del sistema, los objetivos que debe cumplir respecto a unos grados de rendimiento, seguridad, disponibilidad y flexibilidad, sin olvidar el importante aspecto económico. Como puede observarse, los resultados de este último paso sirven de entrada para dos actividades que se realizan de forma paralela. El diseño de las vistas trata de definir las interfaces para el usuario final y, por otro lado, el diseño conceptual se encarga de examinar la empresa para determinar los tipos de entidades y establecer la relación entre ellas. Existe un vínculo entre el diseño de las vistas y el diseño conceptual. El diseño conceptual puede interpretarse como la integración de las vistas del usuario, este aspecto es de vital importancia ya que el modelo conceptual debería soportar no sólo las aplicaciones existentes, sino que debería estar preparado para futuras aplicaciones. En el diseño conceptual y de las vistas del usuario se especificarán las entidades de datos y se determinarán las aplicaciones que funcionarán sobre la base de datos, así mismo, se recopilarán datos estadísticos o estimaciones sobre la actividad de estas aplicaciones. Dichas estimaciones deberían girar en torno a la frecuencia de acceso, por parte de una aplicación, a las distintas relaciones de las que hace uso, podría afinarse más anotando los atributos de la relación a la que accede. Desarrollado el trabajo hasta aquí, se puede abordar la confección del esquema conceptual global. Este esquema y la información relativa al acceso a los datos sirven de entrada al paso distintivo: el diseño de la distribución. El objetivo de esta etapa consiste en diseñar los esquemas conceptuales locales que se distribuirán a lo largo de todos los puestos del sistema distribuido. Sería posible tratar cada entidad como una unidad de distribución; en el caso del modelo relacional, cada entidad se corresponde con una relación. Resulta bastante frecuente dividir cada relación en subrelaciones menores denominadas fragmentos que luego se ubican en uno u otro sitio.
De ahí, que el proceso del diseño de la distribución conste de dos actividades fundamentales: la fragmentación y la asignación. El último paso del diseño de la distribución es el diseño físico, el cual proyecta los esquemas conceptuales locales sobre los dispositivos de almacenamiento físico disponibles en los distintos sitios. Las entradas para este paso son los esquemas conceptuales locales y la información de acceso a los fragmentos. Por último, se sabe que la actividad de desarrollo y diseño es un tipo de proceso que necesita de una motorización y un ajuste periódicos, para que si se llegan a producir desviaciones, se pueda retornar a alguna de las fases anteriores.
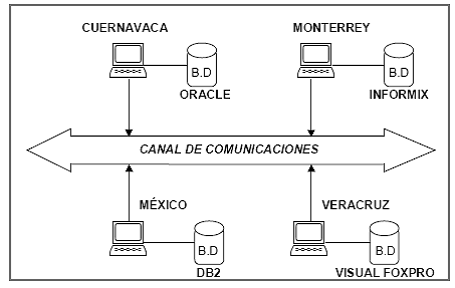
Los sistemas cliente/servidor involucran varias computadoras conectadas a una red. Las computadoras que procesan programas de aplicaciones se conocen como clientes y las que procesan bases de datos se conocen como servidor.
Arquitectura Cliente Servidor
Un sistema cliente servidor puede tener varios servidores de procesamiento de bases de datos, cuando esto ocurre cada servidor debe procesar una base de datos distinta. Cuando dos o más servidores procesan una misma base de datos, el sistema no es considerado cliente servidor, más bien, es conocido como sistema de base de datos distribuido.
Funciones del cliente:
Funciones del servidor:
Primeramente se debe de contar con heterogeneidad de los datos, para que puedan ser usados para formular consultas. Tenemos los siguientes ejemplos:


Así como también necesitamos contar con:
También se cuenta con la estrategia de descomposición de las fuentes, q consiste en que según las fuentes q pidan cierto tipo de datos sean las atendidas con mayor velocidad.
Para poder optimizar una consulta necesitamos tener claras las propiedades del algebra relacional para asegurar la re formulación de la consulta, al optimizar una consulta obtenemos los siguientes beneficios:
1.3 Procesamiento de operaciones de actualización distribuida
Arquitectura Cliente Servidor
Un sistema cliente servidor puede tener varios servidores de procesamiento de bases de datos, cuando esto ocurre cada servidor debe procesar una base de datos distinta. Cuando dos o más servidores procesan una misma base de datos, el sistema no es considerado cliente servidor, más bien, es conocido como sistema de base de datos distribuido.
Funciones del cliente:
- Administrar la interfaz de usuario.
- Aceptar datos del usuario.
- Procesar la lógica de la aplicación.
- Generar las solicitudes para la base de datos.
- Trasmitir las solicitudes de la base de datos al servidor.
- Recibir los resultados del servidor.
- Dar formatos a los resultados.
Funciones del servidor:
- Aceptar las solicitudes de la base de datos de los clientes.
- Procesar las solicitudes de los clientes.
- Dar formato a los resultados y trasmitirlos al cliente.
- Llevar a cabo la verificación de integridad.
- Mantener los datos generales de la base de datos.
- Proporcionar control de acceso concurrente.
- Llevar a cabo la recuperación.
- Optimizar el procesamiento de consulta/actualización.
1.4 Procesamiento de consultas distribuidas
Primeramente se debe de contar con heterogeneidad de los datos, para que puedan ser usados para formular consultas. Tenemos los siguientes ejemplos:
BD CENTRALIZADA

BD DISTRUIBUIDA

Así como también necesitamos contar con:
- Localización de los datos para generar reglas heuristicas
- Descomposición de consultas en paralelo en cada nodo
- Reducir la cantidad de datos a transferir en la red
ESTRATEGIAS DE PROCESAMIENTO DE CONSULTAS DE BASES DE DATOS DISTRIBUIDAS
Contamos con la estrategia de Re formulación de consultas, que nos sirve para encontrar q la información que nos va a proveer sea solo la que se le pidió por la fuenteTambién se cuenta con la estrategia de descomposición de las fuentes, q consiste en que según las fuentes q pidan cierto tipo de datos sean las atendidas con mayor velocidad.
OPTIMIZACIÓN DE CONSULTAS DISTRIBUIDAS
Para poder optimizar una consulta necesitamos tener claras las propiedades del algebra relacional para asegurar la re formulación de la consulta, al optimizar una consulta obtenemos los siguientes beneficios:
- minimizar costos
- Reducir espacios de comunicaciones
- Seguridad en envios de informacion.
1.5 Manejo de Transacciones
Una transacción en un Sistema de Gestión de Bases de Datos (SGBD), es un conjunto de órdenes que se ejecutan formando una unidad de trabajo, es decir, en forma indivisible o atómica.Un SGBD se dice transaccional, si es capaz de mantener la integridad de los datos, haciendo que estas transacciones no puedan finalizar en un estado intermedio. Cuando por alguna causa el sistema debe cancelar la transacción, empieza a deshacer las órdenes ejecutadas hasta dejar la base de datos en su estado inicial (llamado punto de integridad), como si la orden de la transacción nunca se hubiese realizado.Para esto, el lenguaje de consulta de datos SQL (Structured Query Language), provee los mecanismos para especificar que un conjunto de acciones deben constituir una transacción.BEGIN TRAN: Especifica que va a empezar una transacción.COMMIT TRAN: Le indica al motor que puede considerar la transacción completada con éxito.ROLLBACK TRAN: Indica que se ha alcanzado un fallo y que debe restablecer la base al punto de integridad.En un sistema ideal, las transacciones deberían garantizar todas las propiedades ACID; en la práctica, a veces alguna de estas propiedades se simplifica o debilita con vistas a obtener un mejor rendimiento.Un ejemplo de transacciónUn ejemplo habitual de transacción es el traspaso de una cantidad de dinero entre cuentas bancarias. Normalmente se realiza mediante dos operaciones distintas, una en la que se decrementa el saldo de la cuenta origen y otra en la que incrementamos el saldo de la cuenta destino. Para garantizar la atomicidad del sistema (es decir, para que no aparezca o desaparezca dinero), las dos operaciones deben ser atómicas, es decir, el sistema debe garantizar que, bajo cualquier circunstancia (incluso una caída del sistema), el resultado final es que, o bien se han realizado las dos operaciones, o bien no se ha realizado ninguna.
Muy buen trabajo, Saludos
ResponderEliminarLucky Club Casino site【2021】features and analysis
ResponderEliminarLucky Club Casino | Try your luck in the luckyclub casino with all your favourite slots and games. Try for free, no download & no registration required.